Sara Weisweaver, PhD; Rhyan Johnson; Sarah Fairweather; Alison Ma; Jordan Hoskins; Michael Petrochuk
1
WellSaid Labs Research
Abstract.
Despite recent progress in generative speech modeling, generating high-quality, diverse samples from complex
datasets remains an elusive goal.
This work introduces HINTS, a novel generative model architecture combining state-of-the-art neural text-to-speech (TTS) and
contextual annotations.
We learn a separate mapping network that accepts any manner of supervised annotations for controlling the
generator, allowing for scale-specific
modulation and interpolation operations such as loudness and tempo adjustments. Such a setup ensures that our
annotations are consistent,
interpretable, and context-aware. Audio samples are available below. A beta model built on the HINTS architecture is available on wellsaidlabs.com.
Introduction
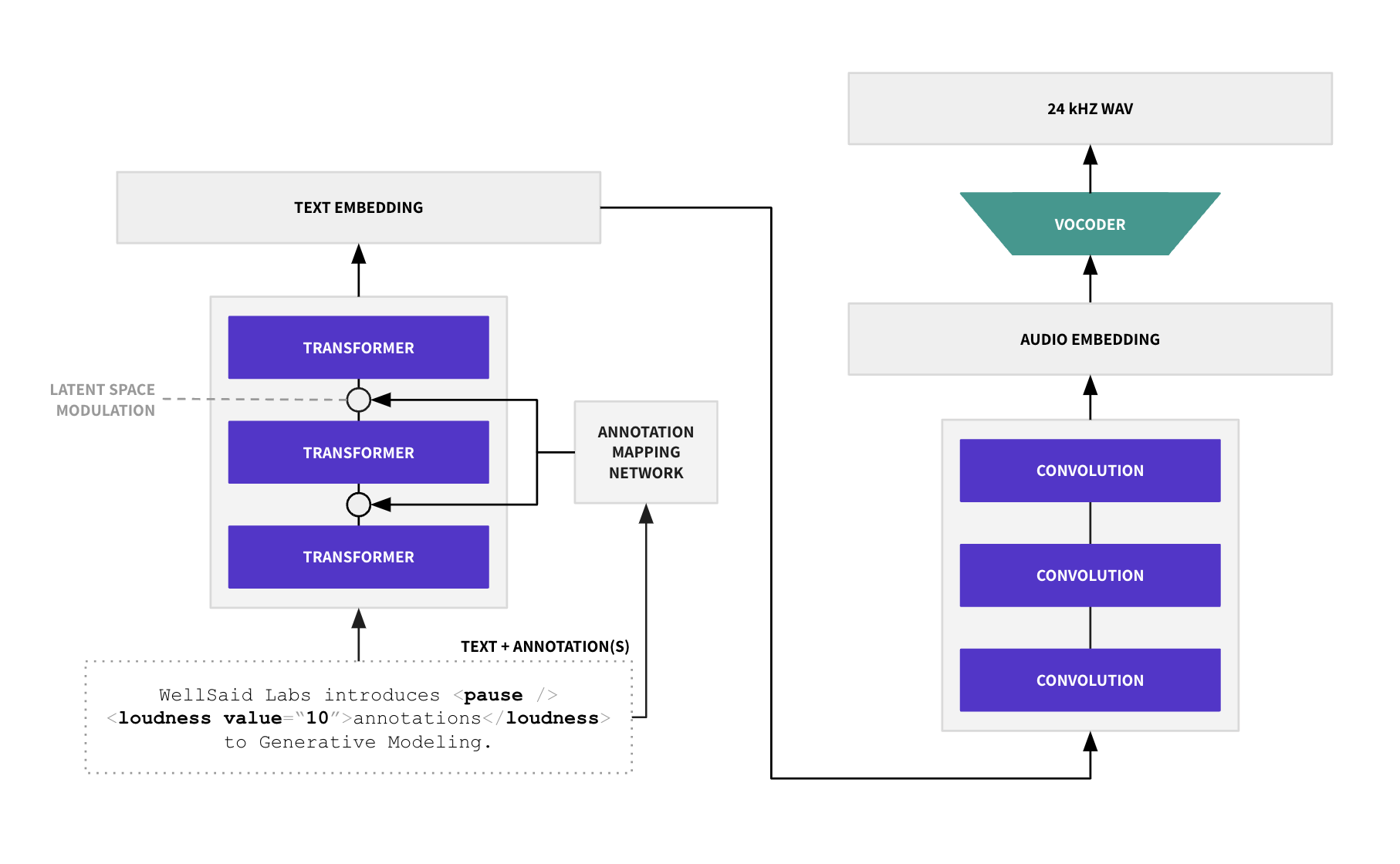
Image illustrates a Cues TTS model with an Annotation Mapping Network (AMN)
for controlling speech synthesis.
In recent years, generative models have ushered in a paradigm shift in content production. Despite their
transformative capabilities, ensuring these
models adhere to specific creative preferences remains challenging. The prevailing method for controlling
generative models is by using natural language
descriptions (i.e., prompts). However, many artistic preferences are nuanced and challenging to describe.
The method introduced in StyleGAN2 and its related
models offers an alternative approach. StyleGAN decouples latent spaces, enabling precise manipulations that
range from high-level attributes to finer details. These controls are not only precise and interpolable but are
also interpretable and context-aware.
Today, we announce a breakthrough in generative modeling for speech synthesis: HINTS (Highly Intuitive
Naturally Tailored Speech).
Our flagship text-to-speech model learns a separate mapping network that maps from contextual annotations (cues)
to a latent space 𝒲 that controls
the generator. This allows for generating high-quality and diverse performances of the same script and speaker
through a consistent, interpretable,
and context-aware mechanism.
Initially, we studied loudness and tempo cues, addressing their historical challenges using this framework. Where
loudness controls traditionally vary decibel outputs, our loudness cue allows for a range of performances that vary
in timbre, which is important for natural prosody. Similarly, our tempo cue does not modify pitch, addressing the
complex inverse relationship between frequency and time. Both cue options, when applied individually or nested,
allow for an expansive range of realistically synthesized expressive and performative audio.
This general framework supports many types of cues. We will be releasing more soon. We include audio samples
below.
Please email our CTO, Michael Petrochuk (michael [at] wellsaidlabs.com), with any questions.
Range and Diversity
In a novel approach, we use annotations alone to successfully guide the model into comprehensive possible points
in the solution space for a single target
speaker using the same sample script.
Sample set 1 We use annotations to craft three distinct listener-friendly versions of the same script. Sample 1D includes
a tempo annotation, a loudness annotation, and a tempo annotation nested inside a loudness annotation.
Speaker: Ben D.
Style: Narration
Source speaker language & location: English, South Africa
Descriptor
Text Input
Audio Output
1A
No annotations
Time for a quick Knowledge Check! Please read the questions
carefully before selecting your answers.
1B
Call to action slowed
Time for a quick Knowledge Check! Please <tempo value="0.5">
read the questions carefully</tempo> before selecting your
answers.
1C
Activity name made louder and slower
Time for a quick <tempo value="0.5"><loudness value="6">
Knowledge Check</loudness></tempo>! Please read the questions
carefully before selecting your answers.
1D
Focus on eliciting user response
Time <loudness value="8">for a quick Knowledge Check
</loudness>! Please <tempo value="0.5">read the questions
carefully</tempo> <tempo value="0.6"><loudness value="10">
before</loudness></tempo> selecting your answers.
Sample set 2 We show how a large area of the solution space can be represented by applying maximum and minimum
value annotations. Sample 2F shows how cues can be used to emphasize and slow down the key
technical information in this passage.
Speaker: Terra G.
Style: Narration
Source speaker language & location: English, United States
Descriptor
Text Input
Audio Output
2A
No annotations
Each of these products requires an HCS container label.
2B
Louder
<loudness value="10">Each of these products requires an HCS
container label</loudness>.
2C
Quieter
<loudness value="-20">Each of these products requires an HCS
container label</loudness>.
2D
Slower
<tempo value="0.5">Each of these products requires an HCS container
label</tempo>.
2E
Faster
<tempo value="2.5">Each of these products requires an HCS container
label</tempo>.
2F
Key information emphasized
Each of these products requires <tempo value="0.8"><loudness
value="2">an HCS container label</loudness></tempo>.
Sample set 3 Our catalog of avatars is responsive to cues. Cues can be nested, even at maximum
levels.
Speaker: Alan T.
Style: Narration
Source speaker language & location: English, United Kingdom
Descriptor
Text Input
Audio Output
3A
No annotations
A large rose-tree stood near the entrance of the garden: the roses
growing on it were white, but there were three gardeners at it,
busily painting them red.
3B
Faster
<tempo value="2.5">A large rose-tree stood near the entrance of the
garden: the roses growing on it were white, but there were three
gardeners at it, busily painting them red</tempo>.
3C
Slower
<tempo value="0.7">A large rose-tree stood near the entrance of the
garden: the roses growing on it were white, but there were three
gardeners at it, busily painting them red</tempo>.
3D
Quieter
<loudness value="-20">A large rose-tree stood near the entrance of
the garden: the roses growing on it were white, but there were
three gardeners at it, busily painting them red</loudness>.
3E
Louder
<loudness value="10">A large rose-tree stood near the entrance of
the garden: the roses growing on it were white, but there were
three gardeners at it, busily painting them red</loudness>.
3F
Louder and Faster
<tempo value="1.9"><loudness value="6">A large rose-tree stood near
the entrance of the garden: the roses growing on it were white, but
there were three gardeners at it, busily painting them
red</loudness></tempo>.
3G
Louder and Slower
<tempo value="0.7"><loudness value="6">A large rose-tree stood near
the entrance of the garden: the roses growing on it were white, but
there were three gardeners at it, busily painting them
red</loudness></tempo>.
3H
Slower and Quieter
<tempo value="0.7"><loudness value="-8">A large rose-tree stood
near the entrance of the garden: the roses growing on it were
white, but there were three gardeners at it, busily painting them
red</loudness></tempo>.
3I
Quieter and Faster
<tempo value="1.9"><loudness value="-8">A large rose-tree stood
near the entrance of the garden: the roses growing on it were
white, but there were three gardeners at it, busily painting them
red</loudness></tempo>.
Sample set 4 Annotation combinations, particularly for texts subject to actor delivery nuances,
result in audio clips exhibiting diverse emotional tonalities.
Speaker: Jordan T.
Style: Narration
Source speaker language & location: English, United States
Descriptor
Text Input
Audio Output
4A
No annotations
I didn’t say you were wrong.
4B
Casual, off-hand effect
<tempo value="2.2"><loudness value="8">I didn't say you were
wrong</loudness></tempo>.
4C
Measured, emotive effect
<tempo value="0.7"><loudness value="-12">I didn't say you were
wrong</loudness></tempo>.
Robustness
The model responds intuitively to a variety of inputs: various cue and text lengths, various
annotation combinations, and various nesting patterns.
Sample set 5 Annotations allow users to direct the AI to see their artistic vision through. Avatars respond to cues
consistent with their own individual styles.
Speaker: Paige L.
Style: Narration
Source speaker language & location: English, United States
Descriptor
Text Input
Audio Output
5A
Editor's choice: entire clip slowed, with loudness increased on key phrases
<tempo value="0.6">In recent years, generative models have ushered
in a paradigm shift in <respell value="KAHN-tehnt">content
</respell> production. <loudness value="12">Despite</loudness>
their <respell value="trans-FOR-muh-dihv">transformative</respell>
capabilities, ensuring these models adhere to specific creative
preferences remains challenging. The <loudness value="12">
prevailing method</loudness> for controlling generative models is
by using natural language descriptions (meaning, prompts). However,
many artistic preferences are often nuanced and more challenging to
describe</tempo>.
Speaker: Paul B.
Style: Promo
Source speaker language & location: English, United States
Descriptor
Text Input
Audio Output
5B
Paced (pauses lengthened) and directed for short ad to appear on social media
Come with me, and discover an <tempo value=“0.7”><loudness
value="-2">icy world of refreshment</loudness></tempo><tempo
value=“0.6”><loudness value="-50">. </loudness></tempo>New <respell
value="BAWSK">Bosc</respell> <tempo value=“2”>is here</tempo>!
Chillingly crisp and clear<tempo value="0.6"><loudness
value="-50">. </loudness></tempo><respell value="BAWSK">
Bosc</respell>... <tempo value="0.8">bubbly cold refreshment
</tempo> with that <tempo value="0.8">light, luscious <respell
value="PERR">pear</respell> flavor</tempo>. <tempo value="1.6">
Lemon and lime are fine</tempo>. <respell value="BAWSK">
Bosc</respell> is better<tempo value="0.6"><loudness value="-50">.
</loudness></tempo>Crack open a world <tempo value="0.8"><loudness
value="4">of icy cool refreshment</loudness></tempo>.
Speaker: Ramona J.
Style: Promo
Source speaker language & location: English, United States
Descriptor
Text Input
Audio Output
5C
Paced (pauses lengthened) and directed for short ad to appear on social media
Come with me, and discover an <tempo value=“0.7”><loudness
value="-2">icy world of refreshment</loudness></tempo><tempo
value=“0.6”><loudness value="-50">. </loudness></tempo>New <respell
value="BAWSK">Bosc</respell> <tempo value=“2”>is here</tempo>!
Chillingly crisp and clear<tempo value="0.6"><loudness
value="-50">. </loudness></tempo><respell value="BAWSK">
Bosc</respell>... <tempo value="0.8">bubbly cold refreshment
</tempo> with that <tempo value="0.8">light, luscious <respell
value="PERR">pear</respell> flavor</tempo>. <tempo value="1.6">
Lemon and lime are fine</tempo>. <respell value="BAWSK">
Bosc</respell> is better<tempo value="0.6"><loudness value="-50">.
</loudness></tempo>Crack open a world <tempo value="0.8"><loudness
value="4">of icy cool</loudness></tempo> refreshment.
Sample set 6 Annotations can be applied to very long passages with no degradation. An annotation applied to a penultimate
paragraph results in a corresponding expected result. Moreover, the final paragraph is delivered in the default,
non-annotated style with no degradation.
Speaker: Lulu G.
Style: Narration
Source speaker language & location: English, United States
Descriptor
Text Input
Audio Output
6A
4239 characters generated in a single take with no annotations and no degradation.
8-track cartridge.
From Wikipedia, the free encyclopedia.
The 8-track tape is a magnetic-tape sound-recording technology that
was popular from the mid-1960s to the early 1980s, when the compact
cassette, which pre-dated the 8-track system, surpassed it in
popularity for pre-recorded music.
[Full script has been truncated]
In the U.S., eight-track cartridges were phased out of retail
stores in late 1982 and early 1983. However, some titles were still
available as eight-track tapes through Columbia House and RCA Music
Service Record Clubs until late 1988. Until 1990, Radio Shack
(Tandy Corporation) continued to sell blank eight-track cartridges
and players for home recording use under its Realistic brand.
6B
4239 characters generated in a single take with second to last paragraph annotated. The model shows no
degradation
in the annotated portion, and resumes normal loudness and tempo for the final paragraph.
8-track cartridge.
From Wikipedia, the free encyclopedia.
The 8-track tape is a magnetic-tape sound-recording technology...
[Full script has been truncated; cued audio starts at 3:53]
<tempo value="0.6"><loudness value="4">1978 was the peak year
for 8-track sales in the United States, with sales declining
rapidly from then on. Eight-track players became less common in
homes and vehicles in the late 1970s. The compact cassette had
arrived in 1963</loudness></tempo>.
In the U.S., eight-track cartridges were phased out of retail
stores in late 1982 and early 1983. However, some titles were still
available as eight-track tapes through Columbia House and RCA Music
Service Record Clubs until late 1988. Until 1990, Radio Shack
(Tandy Corporation) continued to sell blank eight-track cartridges
and players for home recording use under its Realistic brand.
6C
4239 characters generated in a single take with entire passage annotated and no degradation.
<tempo value="1.4"><loudness value="-2">8-track cartridge.
From Wikipedia, the free encyclopedia.
The 8-track tape is a magnetic-tape sound-recording technology...
[Full script has been truncated]
In the U.S., eight-track cartridges were phased out of retail
stores in late 1982 and early 1983. However, some titles were still
available as eight-track tapes through Columbia House and RCA Music
Service Record Clubs until late 1988. Until 1990, Radio Shack
(Tandy Corporation) continued to sell blank eight-track cartridges
and players for home recording use under its Realistic brand.
</loudness></tempo>.
Interpolation
The model can generate audio between a range of annotation values, allowing for precise control. In the following sample sets, we
illustrate the model's capacity for incremental increases or decreases of specific audio elements in a scaled manner.
We show the control sentence, which is unannotated, alongside incremental increases or decreases in loudness and tempo.
Our examples match what users would actually want to do, such as:
increasing the loudness of dialogue in an audiobook clip;
decreasing the loudness of a confession;
increasing the pace for a legal disclaimer; and
decreasing the pace for a technical definition to aid comprehension.
Sample set 7 Dialogue from this passage in Kafka's Metamorphosis is made gradually louder.
Speaker: Garry J.
Style: Narration
Source speaker language & location: English, Canada
Descriptor
Text Input
Audio Output
7A
No annotations
“Listen”, said the chief clerk in the next room, “he’s turning the
key.”
7B
Dialogue louder at 2
“<loudness value="2">Listen</loudness>," said the chief clerk in
the next room; “<loudness value="2">he’s turning the
key</loudness>.”
7C
Dialogue louder at 4
“<loudness value="4">Listen</loudness>," said the chief clerk in
the next room; “<loudness value="4">he’s turning the
key</loudness>.”
7D
Dialogue louder at 6
“<loudness value="6">Listen</loudness>," said the chief clerk in
the next room; “<loudness value="6">he’s turning the
key</loudness>.”
7E
Dialogue louder at 8
“<loudness value="8">Listen</loudness>," said the chief clerk in
the next room; “<loudness value="8">he’s turning the
key</loudness>.”
7F
Dialogue full user-facing loudness at 10
“<loudness value="10">Listen</loudness>," said the chief clerk in
the next room; “<loudness value="10">he’s turning the
key</loudness>.”
Sample set 8 The middle sentence of this invented customer dialogue is gradually quietened.
Speaker: Zach E.
Style: Promo
Source speaker language & location: English, United States
Descriptor
Text Input
Audio Output
8A
No annotations
Thanks for asking. I haven't been able to find the right links. Can
you help me?
8B
Middle sentence quieter at -2
Thanks for asking. <loudness value="-2">I haven't been able to find
the right links</loudness>. Can you help me?
8C
Middle sentence quieter at -4
Thanks for asking. <loudness value="-4">I haven't been able to find
the right links</loudness>. Can you help me?
8D
Middle sentence quieter at -8
Thanks for asking. <loudness value="-8">I haven't been able to find
the right links</loudness>. Can you help me?
8E
Middle sentence quieter at -12
Thanks for asking. <loudness value="-12">I haven't been able to find
the right links</loudness>. Can you help me?
8F
Middle sentence max user-facing quiet at -20
Thanks for asking. <loudness value="-20">I haven't been able to find
the right links</loudness>. Can you help me?
Sample set 9 Content warning is delivered at an incrementally increased pace.
Speaker: Sofia H.
Style: Conversational
Source speaker language & location: English, United States
Descriptor
Text Input
Audio Output
9A
No annotations
The following preview has been rated for mature
audiences only. Viewer discretion is advised.
9B
Faster at 1.3
<tempo value="1.3">The following preview has been rated for mature
audiences only. Viewer discretion is advised</tempo>.
9C
Faster at 1.6
<tempo value="1.6">The following preview has been rated for mature
audiences only. Viewer discretion is advised</tempo>.
9D
Faster at 1.9
<tempo value="1.9">The following preview has been rated for mature
audiences only. Viewer discretion is advised</tempo>.
9E
Faster at 2.2
<tempo value="2.2">The following preview has been rated for mature
audiences only. Viewer discretion is advised</tempo>.
9F
Fastest user-facing pace at 2.5
<tempo value="2.5">The following preview has been rated for mature
audiences only. Viewer discretion is advised</tempo>.
Sample set 10 In this definiton of Boyle's Law provided by Wikipedia, the key defining phrase is delivered at an
incrementally decreased pace. The respelling nested inside the slowed passage responds as expected, with
no pronunciation degradation.
Speaker: Michael V.
Style: Narration
Source speaker language & location: English, United States
Descriptor
Text Input
Audio Output
10A
No speed annotations, one respelling cue
Boyle's law states, the absolute pressure <respell value=
"ihg-ZUR-duhd">exerted</respell> by a given mass of an ideal gas
is inversely proportional to the volume it occupies, if the
temperature and amount of gas remain unchanged within a closed
system.
10B
Definition slower at 0.9
Boyle's law states, <tempo value="0.9">the absolute pressure
<respell value="ihg-ZUR-duhd">exerted</respell> by a given mass
of an ideal gas is inversely proportional to the volume it
occupies</tempo>, if the temperature and amount of gas remain
unchanged within a closed system.
10C
Definition slower at 0.8
Boyle's law states, <tempo value="0.8">the absolute pressure
<respell value="ihg-ZUR-duhd">exerted</respell> by a given mass
of an ideal gas is inversely proportional to the volume it
occupies</tempo>, if the temperature and amount of gas remain
unchanged within a closed system.
10D
Definition slower at 0.7
Boyle's law states, <tempo value="0.7">the absolute pressure
<respell value="ihg-ZUR-duhd">exerted</respell> by a given mass
of an ideal gas is inversely proportional to the volume it
occupies</tempo>, if the temperature and amount of gas remain
unchanged within a closed system.
10E
Definition slower at 0.6
Boyle's law states, <tempo value="0.6">the absolute pressure
<respell value="ihg-ZUR-duhd">exerted</respell> by a given mass
of an ideal gas is inversely proportional to the volume it
occupies</tempo>, if the temperature and amount of gas remain
unchanged within a closed system.
10F
Definition slowest user-facing pace at 0.5
Boyle's law states, <tempo value="0.5">the absolute pressure
<respell value="ihg-ZUR-duhd">exerted</respell> by a given mass
of an ideal gas is inversely proportional to the volume it
occupies</tempo>, if the temperature and amount of gas remain
unchanged within a closed system.
Annotating Silences
Cues can be effectively applied to spaces and punctuation marks to customize pausing and spacing.
Sample set 11 Periods, commas, ellipses, and colons are slowed to create a moment of pause while preserving
each text's prosody.
Speaker: Cameron S.
Style: Narration
Source speaker language & location: English, United States
Descriptor
Text Input
Audio Output
11A
No annotations
Let's pause, and take a moment to think.
11B
Pause lengthened on a comma
Let's pause<loudness value="-20"><tempo value=".18">, </tempo>
</loudness>and take a moment to think.
Speaker: Ali P.
Style: Narration
Source speaker language & location: English, Australia
Descriptor
Text Input
Audio Output
11C
No annotations
Let's do a knowledge check. Which of the following options is
correct?
11D
Pause lengthened on a period
Let's do a knowledge check<tempo value=“0.5”><loudness value=
"-60">. </loudness></tempo>Which of the following options is
correct?
Speaker: Joe F.
Style: Promo
Source speaker language & location: English, United States
Descriptor
Text Input
Audio Output
11E
No annotations
In a town... with only one sheriff... and three tons of banana
peels... who will win... and who will slip...
11F
Pauses lengthened on three periods
In a town<loudness value="-60"><tempo value=".2">... </tempo>
</loudness>with only one sheriff<loudness value="-60"><tempo
value=".2">... </tempo></loudness>and three tons of banana
peels<loudness value="-60"><tempo value=".2">... </tempo>
</loudness>who will win<loudness value="-60"><tempo value=".2">
... </tempo></loudness>and who will slip...
11G
Pauses slightly lengthened on three periods; final phrase slowed and quieted for dramatic effect
In a town<loudness value="-60"><tempo value=".45">... </tempo>
</loudness>with only one sheriff<loudness value="-60"><tempo
value=".45">... </tempo></loudness>and three tons of banana
peels<loudness value="-60"><tempo value=".45">... </tempo>
</loudness>who will win<loudness value="-60"><tempo value=".6">
... </tempo></loudness><tempo value="0.7"><loudness value="-4">
and who will slip</loudness></tempo>...
Speaker: Lulu G.
Style: Narration
Source speaker language & location: English, United States
Descriptor
Text Input
Audio Output
11H
No annotations
Taxonomic characters are the taxonomic attributes that can be used
to provide the evidence from which the phylogeny between taxa are
inferred. Kinds of taxonomic characters include:
Morphological
Physiological
Molecular
Behavioral
Ecological
and Geographic characters
11I
Pause lengthened on a colon
Taxonomic characters are the taxonomic attributes that can be used
to provide the evidence from which the phylogeny between taxa are
inferred. Kinds of taxonomic characters include<tempo
value=“0.2”><loudness value="-60">: </loudness></tempo>
Morphological
Physiological
Molecular
Behavioral
Ecological
and Geographic characters
Annotation Generalization Samples
Within cued performances, the model can push a target speaker’s performance
range beyond what is present in the source speaker’s training data.
Sample set 12 In the following audio samples, we include maximum and minimum portions of
the original gold dataset for loudness (LUFS) and tempo (CPS). These are presented
in comparison to the synthetic voice outputs’ maximum and minimum performances for
loudness and tempo.
Speaker: Lee M.
Style: Narration
Source speaker language & location: English, United States
<loudness value=“-50”>during those first few hours</loudness>
Emergent Behaviors
The model learns annotations in context, such that pronunciation and prosody are impacted
by cues. This demonstrates the model's ability to generalize well. With subsequent training,
this capability may become an emergent ability.
Sample set 13 Extreme tempo and loudness annotations, when nested, can prompt a dramatic performance that
impacts syllabic stress. Extreme slow annotations can prompt the model to spell the annotated word.
Speaker: Damian P.
Style: Promo
Source speaker language & location: English, Canada
Recent evidence suggests that the mammalian brain may avoid
<loudness value="30"><tempo value="0.6">catastrophic
forgetting</tempo></loudness> by protecting previously acquired
knowledge in neocortical circuits.
Speaker: Fiona H.
Style: Narration
Source speaker language & location: English, United Kingdom
Descriptor
Text Input
Audio Output
13B
Extreme slow cue prompts word spelling
What happens if I slow down the word <tempo value="0.2">umbrella
</tempo> in this sentence?
Speaker: Se’Von M.
Style: Narration
Source speaker language & location: English, United States
Descriptor
Text Input
Audio Output
13C
No annotations
do
13D
Extreme slow cue prompts word spelling
<tempo value="0.3">do</tempo>
13E
No annotations
all
13F
Extreme slow cue prompts word spelling
<tempo value="0.26">all</tempo>
Speaker: Genevieve M.
Style: Promo
Source speaker language & location: English, United States
Descriptor
Text Input
Audio Output
13G
Fast cue within user range prompts fast word delivery
<tempo value="3">content</tempo>
13H
Extreme slow cue prompts word spelling
<tempo value="0.3">content</tempo>
Future State
We have shown that the annotation mapping network generalizes
well and is context sensitive, supporting diverse input variability and an expansive annotation range.
This framework can be quickly expanded with additional annotations such as pitch, brightness, fullness, range, and
breath control, in near future releases.
We have already prototyped a pitch annotation:
Speaker: Charlie Z.
Source speaker language & location: English, Canada
Style: Narration
Script: A new art exhibit is drawing crowds at the city’s museum.
Audio Type
Pitch Annotation Value
Audio Output
A
Griffin-Lim
-200Hz
B
Griffin-Lim
+300Hz
With additional training, more data, and subsequent model improvements, we are excited for the creative
applications of this approach.
Ethical Responsibility
Our commitment to the principles of Responsible AI informed the practices and approaches we used for this work.
Specifically, we leaned on the principles of accountability, transparency, and privacy & security.
The tenets of accountability and transparency are reflected in our requirement that we have the
explicit, informed consent
of any individual who records voice datasets for WellSaid Labs. End users can only access target speakers built
from datasets
recorded by voice talent who have provided consent for end-user access. Additionally, annotations do not provide a
means for
end users to guide the model into a different target speaker’s solution space. We limit the collection of data
from other providers
to those that are open source (e.g., LibriSpeech), and voices we create using that open source data are not
available to our users.
The principle of privacy & security drives us to design our systems so that we can protect the privacy of
our users and participants who
provide us with their voice datasets, and reduce opportunities for data or voice avatars to be misused. Our Trust
& Safety team ensures
that all users undergo identity verification when creating an account, and content created on our platform is
subject to robust content
moderation, limiting the creation and release of content that does not align with our Terms of Service.
Baseline Evaluation
We listened to 1700+ audio samples to evaluate the occurrence of common issues in text-to-speech
sequence-to-sequence attention models.
Metric
Interpretation
Goal
WSL Baseline Model
WSL New Model
Initialism Pronunciation
% correct
100%
86.27%
94.12%
Question Intonation (Rising)
% correct
100%
30.83%
38.33%
100 Words Pronunciation
% correct
100%
94.13%
94.58%
Slurring
% occurring
0%
0.00%
0.67%
Word Cutoff
% occurring
0%
0.00%
0.67%
Word Skip
% occurring
0%
0.67%
0.67%
Speaker-Swapping
% occurring
0%
0%
0%
Loudness Inconsistency Across Clip
% occurring
0%
~0%
~0%
Latency
seconds
decreasing
0.5s
0.5s
Target Speakers
total #
increasing
126
106
Dataset
# hours
increasing
560 hours
530 hours
Note. During development, we noted that extreme annotation values force the model’s latent state
representing
one speaker into that of another. The net effect is that the model produces audio using a speaker other than the
target
speaker. Prior to releasing WSL New to users, we implemented per-speaker cue value limitations to specific
ranges within
which speaker swapping does not occur.
Acknowledgments
Contributors. Michael Petrochuk; Sara Weisweaver; Rhyan Johnson; Jordan Hoskins; Sarah Fairweather;
Courtney Mathy; Alecia Murray; Alison Ma; Daniel “Dandie” Swain, Jr.; Jon Delgado; Jessica Petrochuk
A special thank you to the voice talent that make our avatars possible, especially those featured in this
paper: Alan T., Ali P., Ben D., Cameron S., Damian P., Fiona H., Garry J., Genevieve M., Joe F., Jordan T.,
Jude D., Lee M., Lulu G., Michael V., Paige L., Paul B., Ramona J., Se’Von M., Sofia H., Terra G., and Zach E.
Footnotes
1
Authors are ordered by the number of letters in their first name (take me back)
Complete text without tempo and loudness cues is as follows:
8-track cartridge.
From Wikipedia, the free encyclopedia.
The 8-track tape is a magnetic-tape sound-recording technology that was popular from the mid-1960s to the early 1980s, when the compact <respell value="kuh=SEHT">cassette</respell>, which pre-dated the 8-track system, surpassed it in popularity for pre-recorded music.
The format was commonly used in cars and was most popular in the United States and Canada and, to a lesser extent, in the United Kingdom. One advantage of the 8-track tape cartridge was that it could play continuously in an endless loop, and did not have to be "flipped over" to play the entire tape. After about 80 minutes of playing time, the tape would start again at the beginning. Because of the loop, there is no rewind. The only options the consumer has are "play", "fast forward", "record", and "program change".
The Stereo 8 Cartridge was created in 1964 by a consortium led by Bill Lear, of Lear Jet Corporation, along with Ampex, Ford Motor Company, General Motors, Motorola, and RCA Victor Records.
The 8-track tape format is now considered obsolete, although there are collectors who refurbish these tapes and players as well as some bands that issue these tapes as a novelty. Cheap Trick's “The Latest" in 2009 was issued on 8-track, as was Dolly Parton's “A Holly Dolly Christmas” in 2020, the latter with an exclusive bonus track.
.
Technology.
The cartridge's dimensions are approximately 5.25, by 4, by 0.8 inches. The magnetic tape is played at three three-fourth inches per second, is <respell value="WOWND">wound</respell> around a single spool, is about 0.25 inches wide, and contains 8 parallel tracks. The player's head reads two of these tracks at a time for stereo sound. After completing a program, the head mechanically switches to another set of two tracks, creating a characteristic clicking noise.
.
Commercial success.
The popularity of both four-track and eight-track cartridges grew from the booming automobile industry. In September 1965, the Ford Motor Company introduced factory-installed and dealer-installed eight-track tape players as an option on three of its 1966 models (the sporty <respell value="MUH-stayng">Mustang</respell>, luxurious Thunderbird, and high-end Lincoln), and RCA Victor introduced 175 Stereo-8 Cartridges from its RCA Victor and RCA Camden labels of recording artists catalogs. By the 1967 model year, all of Ford's vehicles offered this tape player upgrade option. Most of the initial factory installations were separate players from the radio, but dashboard-mounted 8-track units were offered in combination with an AM radio, as well as with AM-FM receivers.
The 8-track format gained steadily in popularity because of its convenience and portability. Home players were introduced in 1966 that allowed consumers to share tapes between their homes and portable systems. By the late 1960s, the 8-track segment was the largest in the USA consumer electronics market and the popularity of 8-track systems for cars helped generate demand for home units. "Boombox" type portable players were also popular. But, eight-track player-recorders failed to gain wide popularity, and few manufacturers offered them, except for manufacturer Tandy Corporation for its Radio Shack stores. With the availability of cartridge systems for the home, consumers started thinking of eight-tracks as a viable alternative to 33 rpm album-style vinyl records, not only as a convenience for the car. Also by the late 1960s, prerecorded releases on the 8-track tape format began to arrive within a month of the vinyl release. The 8-track format became by far the most popular and offered the largest music library of all the tape systems in the USA.
.
Decline.
1978 was the peak year for 8-track sales in the United States, with sales declining rapidly from then on. Eight-track players became less common in homes and vehicles in the late 1970s. The compact <respell value="kuh=SEHT">cassette</respell> had arrived in 1963.
In the U.S., eight-track cartridges were phased out of retail stores in late 1982 and early 1983. However, some titles were still available as eight-track tapes through Columbia House and RCA Music Service Record Clubs until late 1988. Until 1990, Radio Shack (Tandy Corporation) continued to sell blank eight-track cartridges and players for home recording use under its Realistic brand. (take me back)